
Claude Fable 5 深度解读:Mythos 级模型、价格、安全限制与开发者影响
Anthropic 发布 Claude Fable 5 和 Claude Mythos 5。本文梳理模型定位、1M 上下文、128K 输出、价格、安全回退、开放范围,以及它对 AI 编程和长周期 agent 工作流的实际影响。
文章目录
更新时间:2026-06-10
原文出处:Anthropic 官方公告:Claude Fable 5 and Claude Mythos 5。本文基于 Anthropic 官方公告、Claude API 文档和 AWS 发布信息重新整理、改写和补充分析;图片来自 Anthropic 官方公告。
Anthropic 在 2026 年 6 月 9 日发布了 Claude Fable 5,同时也公布了受限开放的 Claude Mythos 5。单看名字,这次发布容易让人困惑:Fable、Mythos、Opus 之间到底是什么关系?它是不是普通用户现在就该切换的新模型?开发者在 API 和云平台里要注意什么?
简单说,Claude Fable 5 是 Anthropic 目前最强的广泛开放模型,核心能力达到 Mythos 级别,但加了一层更保守的安全限制。Claude Mythos 5 则是同一底层模型的更少限制版本,主要给经过审核的网络安全、防御基础设施和后续部分生命科学合作方使用。
图片来源:Anthropic 官方公告。
Fable 5 到底强在哪里
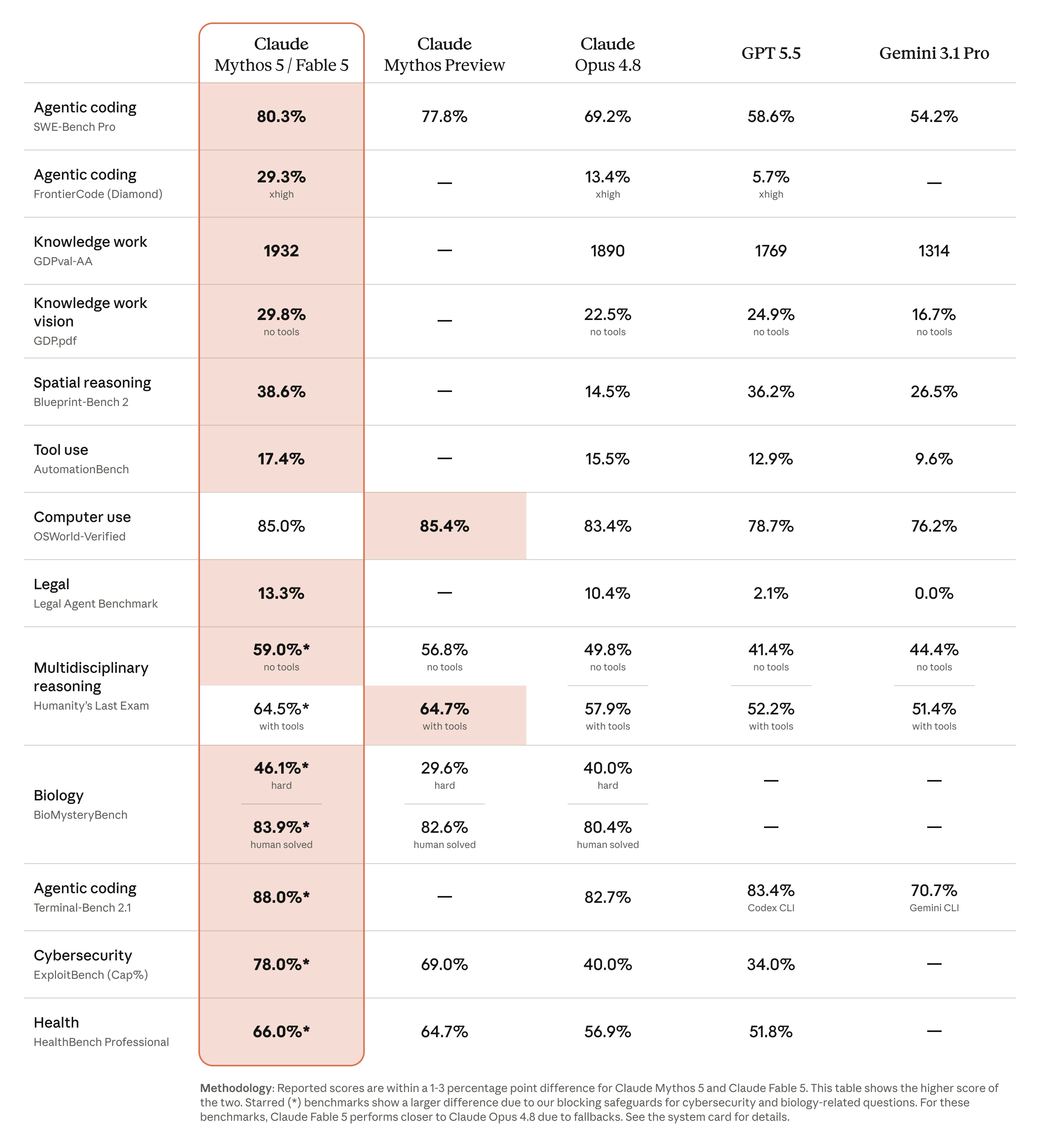
Anthropic 给 Fable 5 的定位很明确:它不是只为了短问答,而是面向更长、更复杂、更异步的工作。官方强调的场景包括大型代码迁移、多阶段研究、复杂文档分析、图表理解、视觉任务和长期 agent 工作流。
这和过去常见的模型升级不太一样。以前新模型常见卖点是“回答更聪明”“代码更强”“速度更快”。Fable 5 的重点更偏向“能坚持做完复杂任务”。也就是说,它要解决的问题不是一次 prompt 里答得漂亮,而是在多小时甚至更长的项目里,能不能规划、执行、检查、修正,并尽量少让人反复盯着。
Claude API 文档里也给出了几个很关键的参数:Fable 5 的 API 模型 ID 是 claude-fable-5,上下文窗口为 100 万 tokens,最大输出为 128K tokens。这个组合对长文档、代码库、研究材料和多文件任务很有意义。不是每个任务都需要这么大的窗口,但一旦你在做代码库级别迁移、跨文档检索、长报告整理,窗口大小会直接影响可操作空间。
图片来源:Anthropic 官方公告。
Fable 5 和 Mythos 5 的关系
这次发布最容易误解的地方,是 Fable 5 和 Mythos 5 的命名。按 Anthropic 的说法,二者是同一底层模型,差别主要在安全分类器和访问权限。
| 项目 | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| 定位 | 广泛开放的最强 Claude 模型 | 受限开放的 Mythos 级模型 |
| API ID | claude-fable-5 | claude-mythos-5 |
| 上下文窗口 | 1M tokens | 1M tokens |
| 最大输出 | 128K tokens | 128K tokens |
| 价格 | 输入 $10/百万 tokens,输出 $50/百万 tokens | 同价 |
| 开放范围 | Claude API、Claude 平台、AWS、Vertex AI、Microsoft Foundry | Project Glasswing 等受审合作方 |
| 主要差别 | 对网络安全、生物、化学、蒸馏等敏感场景更保守 | 部分限制会为合规合作方放开 |
这个设计其实很现实。越强的模型越容易出现“双用途”问题:同样的能力可以帮安全团队找漏洞,也可能被滥用;可以帮科研人员设计实验,也可能触碰危险生物化学场景。Fable 5 是 Anthropic 把 Mythos 级能力推向普通开发者和企业客户的版本,但为了上线范围更大,它必须接受更强的限制。
安全回退会影响使用体验吗
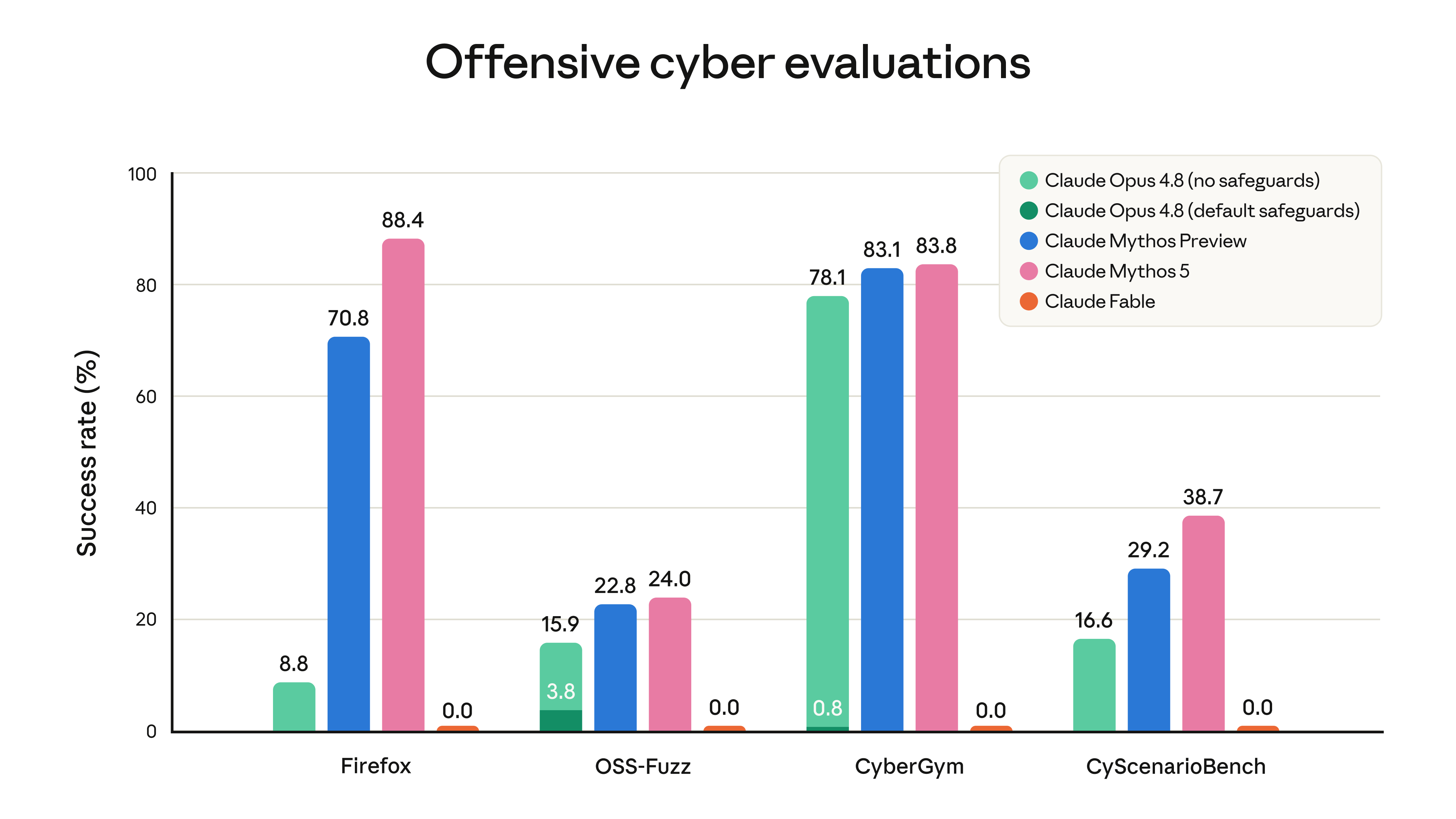
Fable 5 最大的产品变化,是安全分类器触发后会回退到 Claude Opus 4.8。官方提到,涉及网络安全、生物、化学和模型蒸馏的部分请求会被分类器拦截,然后由 Opus 4.8 处理。用户会看到提示,API 用户也需要理解这个回退机制。
从普通使用角度看,大多数写作、代码、产品分析、资料整理、表格和视觉理解任务不应该频繁触发。Anthropic 给出的说法是,超过 95% 的 Fable 会话不会发生回退。但如果你的业务本来就在安全研究、生物信息、化学实验、模型训练数据整理这些领域,就不能只看 benchmark,必须先测试真实工作流里会不会被误判。
这也是我认为国内开发者最需要注意的一点:Fable 5 很强,但不是“无脑替换所有模型”。如果你做的是常规前端、后端、数据分析、文档处理,它可能很适合高难任务;如果你做安全攻防或生命科学相关产品,反而要先评估限制、合规和可用性。
图片来源:Anthropic 官方公告。
图片来源:Anthropic 官方公告。
价格和可用性怎么理解
Fable 5 的 API 价格是输入 $10/百万 tokens、输出 $50/百万 tokens。这个价格比 Opus 4.8 更贵,也明显高于 Sonnet 和 Haiku 级模型,所以它不适合拿来跑所有低价值请求。
更合理的用法是分层:简单问答、短文本改写、常规摘要继续用便宜模型;代码库迁移、复杂架构设计、长报告、多工具 agent、关键交付物审查,再交给 Fable 5。对网站、SaaS 或内部工具来说,这种路由比“全站换最强模型”更实际。
可用性方面,Claude API 和消费型 Enterprise 计划已经开放;订阅计划则分阶段推出。Anthropic 表示,Pro、Max、Team 和 seat-based Enterprise 计划从 6 月 9 日到 6 月 22 日可免费使用 Fable 5,6 月 23 日后如果继续使用可能需要 usage credits,后续会根据容量再调整。
AWS 的公告也补充了云平台侧的细节:Fable 5 已经进入 Amazon Bedrock 和 Claude Platform on AWS,但在 Bedrock 上需要注意数据留存设置。Anthropic 对 Mythos-class 模型要求 30 天数据留存,用于安全监控;这对企业合规不是小事,尤其是金融、医疗、法律和含客户敏感数据的场景。
对 AI 编程工具意味着什么
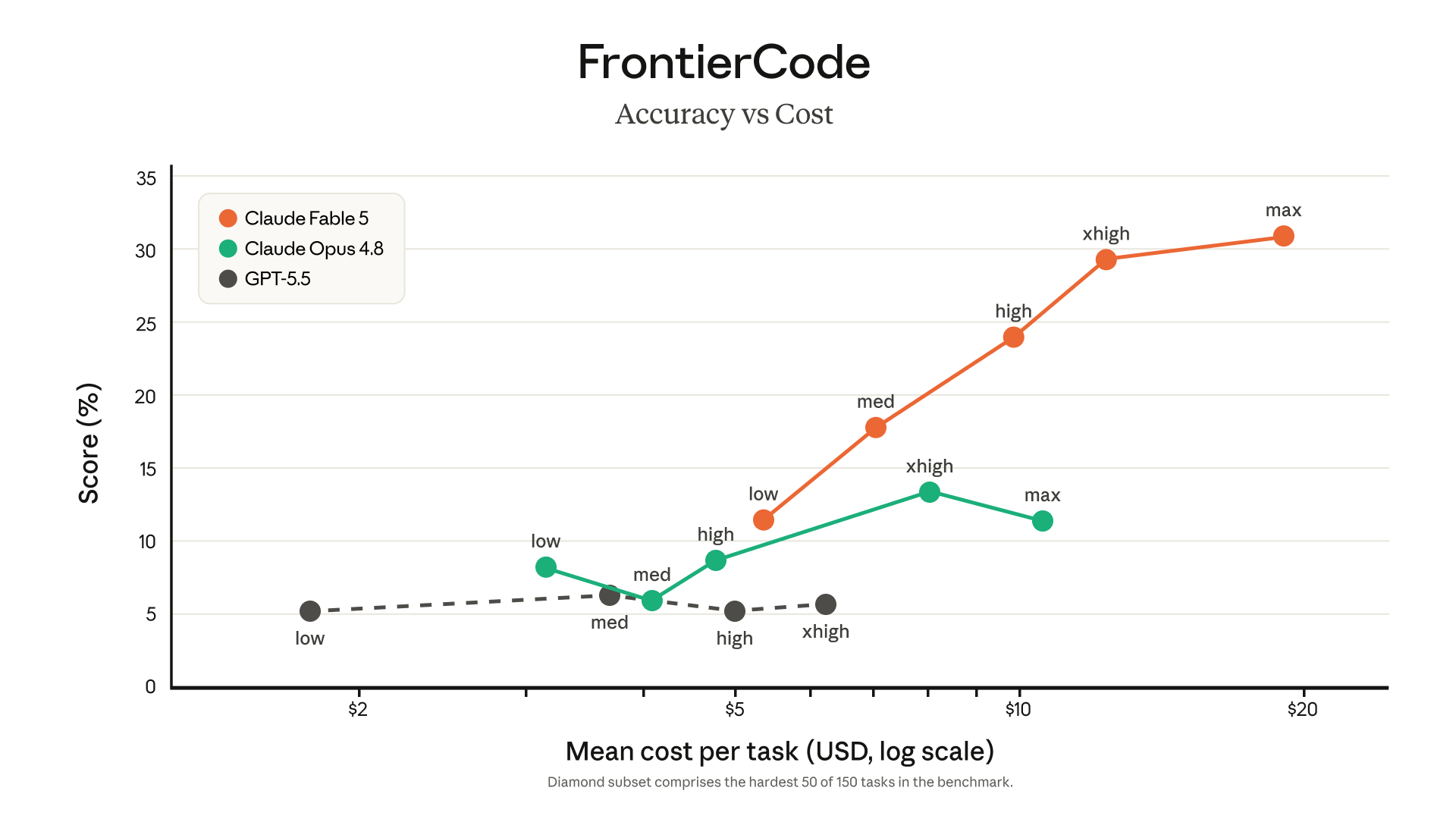
Fable 5 对 AI 编程最大的影响,不只是“代码 benchmark 更高”,而是它可能把 agent 的任务跨度往前推一截。Anthropic 官方和早期客户都在强调长周期工程任务,比如大型迁移、跨文件重构、多阶段验证、按设计稿还原界面、自己写测试再检查结果。
如果你正在用 Claude Code、Cursor、Codex 这类编程工具,Fable 5 值得重点观察三个点:
- 它能不能在大代码库里保持上下文,不重复犯旧错。
- 它生成测试和自检的能力是否真的减少人工返工。
- 它在长任务里的成本是否能被效率提升抵消。
这三个点比单次代码题得分更重要。真正的开发场景不是刷题,而是有旧代码、有约束、有 UI 细节、有线上风险。模型能力越强,越要看它是否能稳定地接受约束,而不是只会一次性生成一大段看起来很完整的代码。
我的建议:先把它当成高难任务模型
如果你只是日常聊天、简单写文案、做几百行以内的小工具,暂时没必要急着把 Fable 5 当默认模型。它的成本和安全机制决定了它更适合处理“低频但高价值”的任务。
更推荐的使用方式是:
- 产品经理:用它整理竞品研究、长需求文档、复杂 PRD 和多来源资料。
- 开发者:用它做代码迁移、架构方案、测试补齐、复杂 bug 定位和大型重构计划。
- 内容团队:用它做深度资料梳理、长文结构、表格解读和多语言版本校对。
- 企业团队:先在非敏感数据上试点,再评估数据留存、权限和合规。
Fable 5 的意义不是替代所有 Claude 模型,而是把 Anthropic 的最高能力放到更广的用户面前。它会让长周期 agent 任务更接近可用,但也带来成本、合规、安全回退和容量限制。真正适合它的地方,是那些用便宜模型反复返工、人工监督成本很高、但任务价值又足够大的场景。
资料来源
原文出处: https://www.anthropic.com/news/claude-fable-5-mythos-5
