
Claude Fable 5 Explained: Mythos-Class Capability, Pricing, Safeguards, and Developer Impact
Anthropic has introduced Claude Fable 5 and Claude Mythos 5. This article explains the model positioning, 1M context window, 128K output, pricing, safeguards, availability, and what it means for coding agents and long-running AI workflows.
Contents
English Version
Updated: 2026-06-10
Original source: Anthropic: Claude Fable 5 and Claude Mythos 5. This article has been rewritten and reorganized for Finding AI Tools based on Anthropic's announcement, Claude API documentation, and AWS launch notes. Images are from Anthropic's official announcement.
Anthropic released Claude Fable 5 on June 9, 2026, alongside the restricted Claude Mythos 5. The names can be confusing at first. Is Fable a normal Claude model? Is Mythos a separate model? Is this something everyday users should switch to immediately?
The short version: Claude Fable 5 is Anthropic's strongest broadly available model so far. It brings Mythos-class capability to general users, but with conservative safety safeguards. Claude Mythos 5 is based on the same underlying model, with fewer restrictions for vetted cybersecurity, infrastructure, and eventually some life sciences partners.
Image source: Anthropic official announcement.
What Makes Fable 5 Different
Anthropic positions Fable 5 as a model for long, complex, asynchronous work rather than quick question-answering. The main use cases include large code migrations, multi-stage research, document-heavy analysis, chart understanding, visual tasks, and long-running agent workflows.
That makes this launch different from the usual "smarter model" upgrade. The important question is not just whether the model gives a better single response. It is whether it can plan, execute, check, revise, and keep working on a hard project with less human babysitting.
The Claude API documentation lists several important technical details: the model ID is claude-fable-5, the context window is 1 million tokens, and the maximum output is 128K tokens. That matters for large codebases, long reports, multi-document work, and workflows where the model needs to hold a lot of state at once.
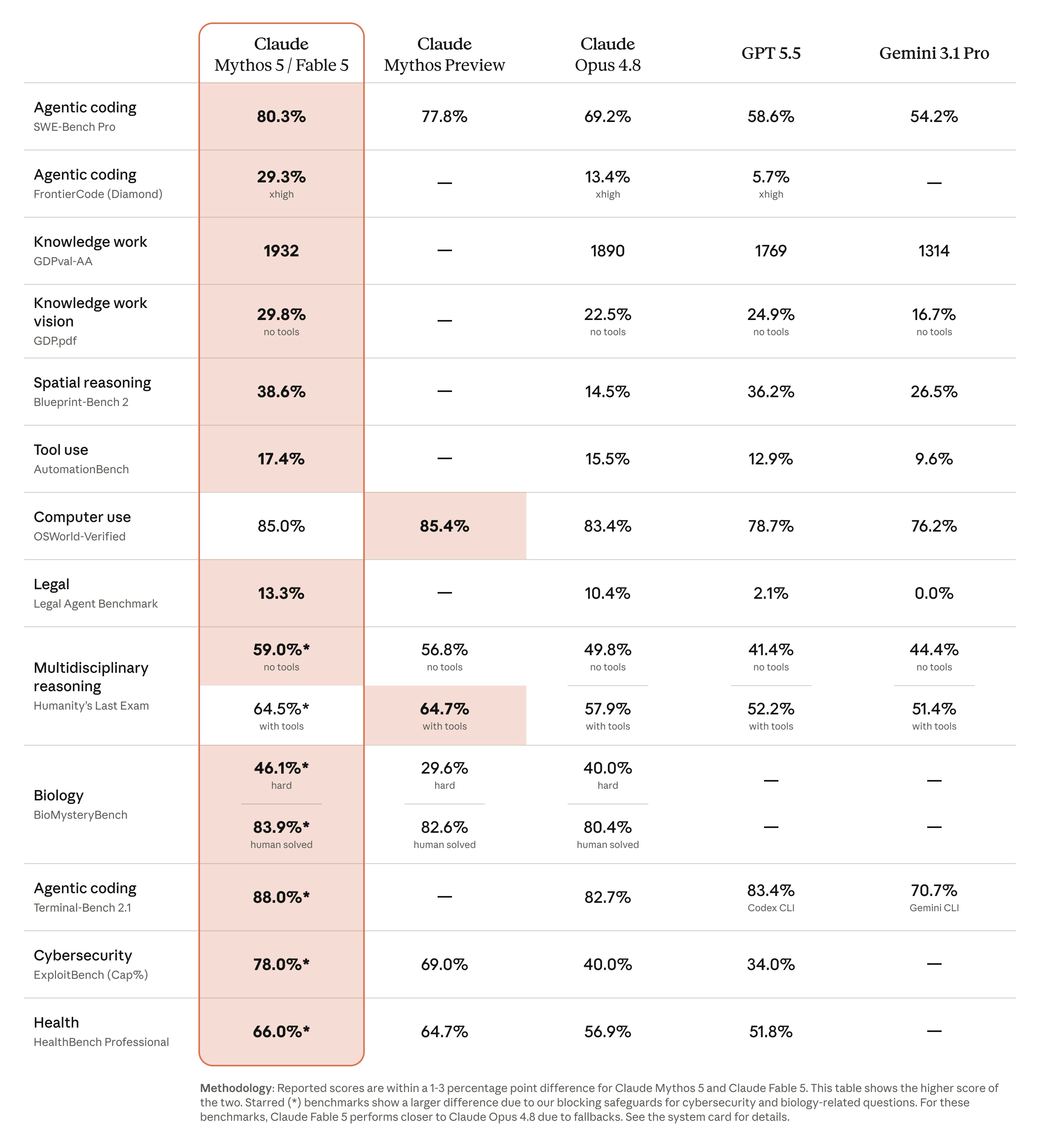
Image source: Anthropic official announcement.
Fable 5 vs Mythos 5
The most important thing to understand is that Fable 5 and Mythos 5 are not completely separate capability tiers. According to Anthropic, they share the same underlying model. The main difference is safeguards and access.
| Item | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Positioning | Strongest broadly available Claude model | Restricted Mythos-class model |
| API ID | claude-fable-5 | claude-mythos-5 |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K tokens | 128K tokens |
| Pricing | $10 / MTok input, $50 / MTok output | Same |
| Availability | Claude API, Claude Platform, AWS, Vertex AI, Microsoft Foundry | Project Glasswing and vetted partners |
| Key difference | Conservative safeguards for sensitive domains | Some safeguards lifted for approved use cases |
The design is practical. More capable models create dual-use concerns. The same capability that helps a defender find vulnerabilities could help an attacker. The same biological reasoning that helps research could also move into risky territory. Fable 5 is Anthropic's attempt to make Mythos-level capability widely usable without opening every high-risk path.
How the Safeguards Affect Usage
Fable 5 introduces a major product behavior: when safety classifiers trigger, the request may fall back to Claude Opus 4.8. Anthropic says this applies to certain cybersecurity, biology, chemistry, and model-distillation topics. Users are informed when this happens, and API customers need to understand how the fallback affects their application.
For normal writing, coding, product analysis, document review, spreadsheet work, and visual understanding, this should not be a daily problem. Anthropic says more than 95% of Fable sessions do not involve fallback. But if your real workflow is in security research, bioinformatics, chemistry, or model training analysis, benchmarks alone are not enough. You need to test your actual prompts and see whether false positives affect the job.
That is the key practical point. Fable 5 may be excellent for difficult general work, but it should not be blindly swapped into every sensitive technical domain without evaluation.
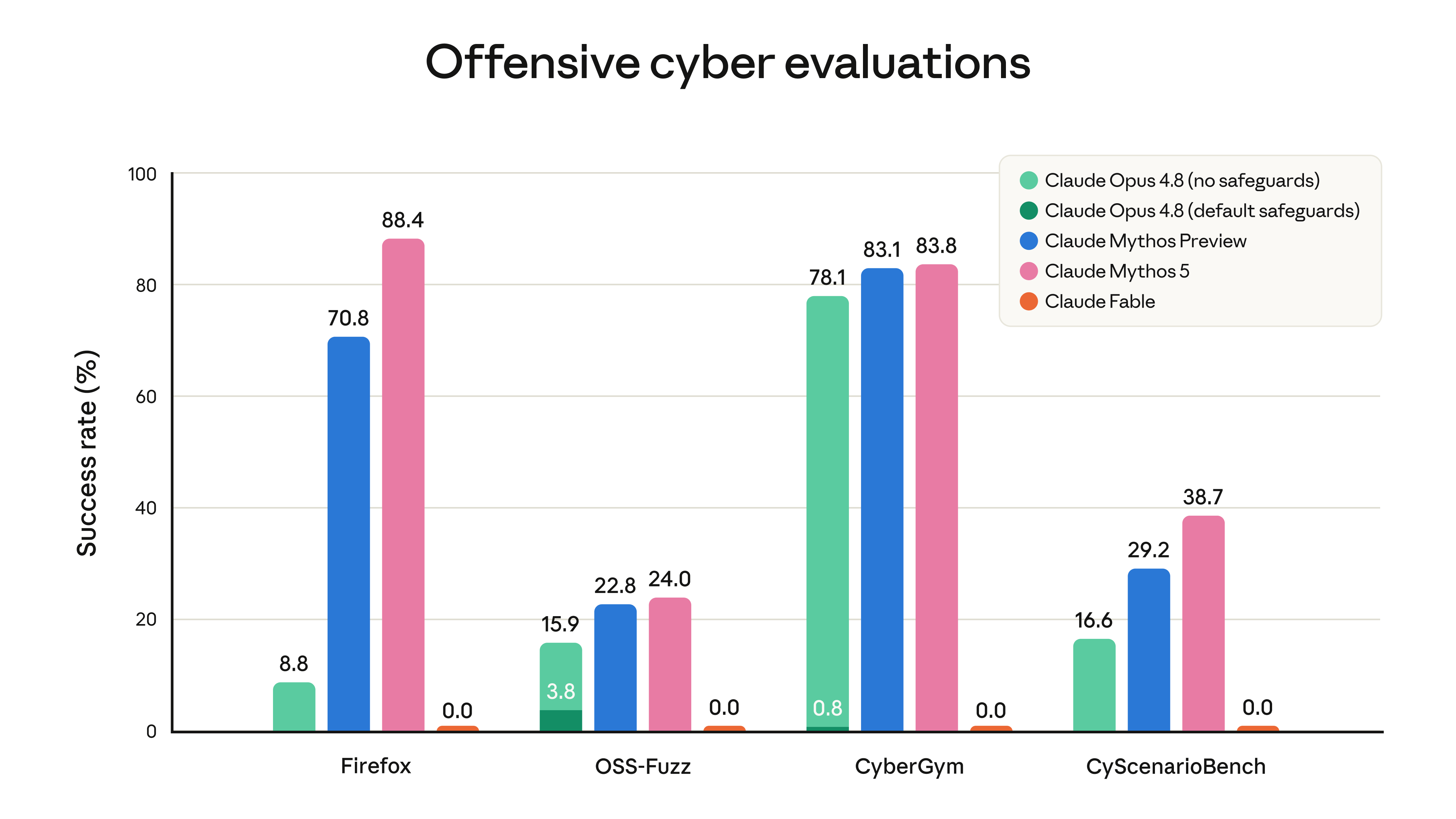
Image source: Anthropic official announcement.
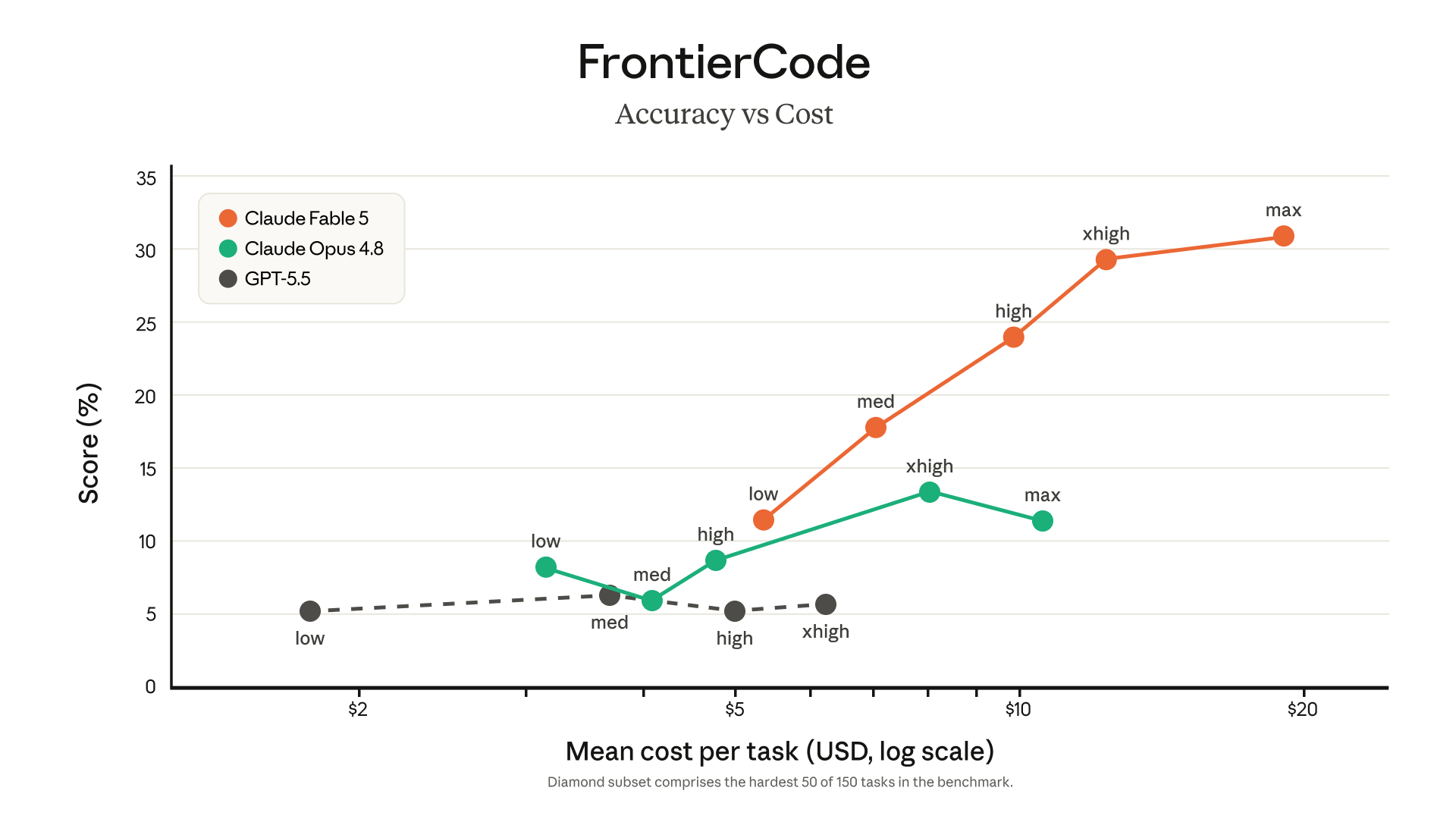
Image source: Anthropic official announcement.
Pricing and Availability
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens. That is more expensive than Opus 4.8 and much more expensive than Sonnet or Haiku-class models, so it should not be used for every low-value request.
A better strategy is routing. Keep cheap models for simple rewriting, short summaries, and routine support tasks. Use Fable 5 for codebase migrations, complex architecture work, long reports, multi-tool agents, and critical deliverable review. For SaaS products and internal tools, that is usually more practical than making the strongest model the default everywhere.
Availability is being phased. Claude API and consumption-based Enterprise plans have access now. Anthropic says Pro, Max, Team, and seat-based Enterprise users can access Fable 5 from June 9 through June 22 at no extra cost. Starting June 23, continued use may require usage credits depending on capacity.
AWS also adds an important enterprise detail. Claude Fable 5 is available on Amazon Bedrock and Claude Platform on AWS, but Bedrock users need to opt into data retention settings. Anthropic requires 30-day data retention for Mythos-class models for safety monitoring. For finance, healthcare, legal, and customer-data-heavy workloads, that is a compliance detail teams should review before production use.
What It Means for AI Coding Tools
The biggest impact for AI coding is not simply a higher coding score. It is the possibility of longer task horizons for coding agents. Anthropic and early customers emphasize large migrations, cross-file refactors, multi-step verification, design-to-code implementation, and the model writing tests to check its own work.
If you use Claude Code, Cursor, Codex, or similar coding agents, Fable 5 is worth evaluating on three things:
- Can it hold context across a large codebase without repeating old mistakes?
- Does its self-testing and self-review actually reduce human rework?
- Does the higher cost pay for itself on long, high-value tasks?
These questions matter more than a single benchmark. Real software work has legacy code, constraints, UI details, production risk, and test expectations. A stronger model is only useful if it can follow those constraints reliably.
Practical Recommendation
If you only need daily chat, short writing, or small scripts, there is no urgent reason to make Fable 5 your default model. Its cost and safeguard behavior make it better suited for low-frequency, high-value tasks.
A more realistic adoption plan:
- Product teams can use it for competitor research, long PRDs, requirement cleanup, and multi-source analysis.
- Developers can use it for migrations, architecture proposals, test coverage, hard bug investigations, and large refactor plans.
- Content teams can use it for deep research, long-form structure, table interpretation, and bilingual review.
- Enterprises should start with non-sensitive data, then review retention, access control, and compliance.
Fable 5 does not replace every Claude model. It expands the top end of what Anthropic can offer to general users. The real opportunity is long-running agent work that was previously too brittle or too expensive to supervise manually. The real tradeoffs are cost, compliance, fallback behavior, and capacity.
Sources
Source: https://www.anthropic.com/news/claude-fable-5-mythos-5
