GPT-5.5 vs Gemini 3.1 Pro 终极对比:性能、成本、隐私全面评测
OpenAI GPT-5.5与Google Gemini 3.1 Pro旗舰对比。从MMLU、编码基准、上下文窗口、API成本到隐私政策,一篇文章看透两大模型的优劣。
文章目录
执行摘要
随着大型语言模型技术的快速迭代,OpenAI 和 Google 纷纷发布了各自的最新旗舰模型——OpenAI 的 GPT-5.5(用于 ChatGPT)和 Google 的 Gemini 3.1 Pro。两者均代表各自阵营在通用智能和多模态推理方面的顶尖水平。
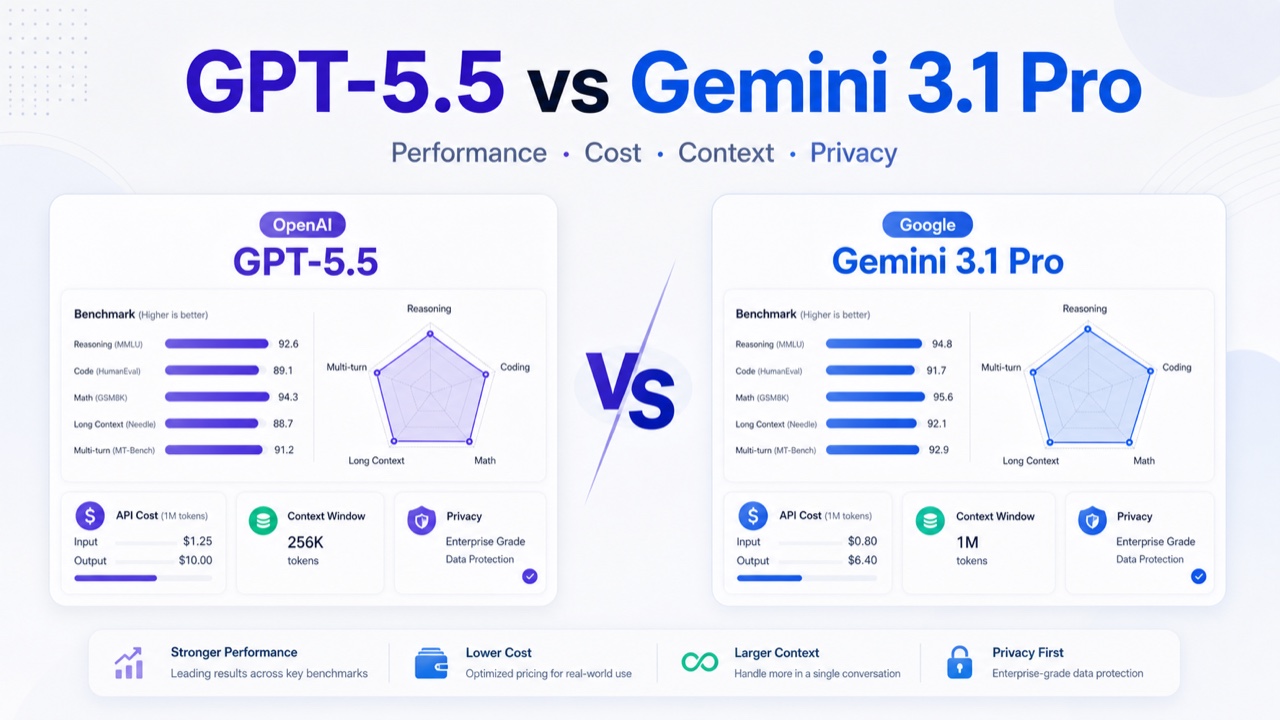
通过对比最新公开资料发现:在多项任务中,Gemini 3.1 Pro 的综合知识与推理能力表现略优于 GPT-5.5。例如在多语言知识问答(MMLU)测试中,Gemini 3.1 Pro 达到 92.6%,而已知的 GPT-4 得分为 86.4%;GPT-5.5 预计也在此基础上有所提升。另一方面,GPT-5.5 在代码生成和工程任务上优势明显:在 OpenAI 的内部编码基准 Terminal-Bench 2.0 中取得 82.7% 准确率,比前代 GPT-5.4 有显著提升。
基础设施方面,两者均支持超大上下文:GPT-5.5 在专业版中提供高达 100万 token 的上下文窗口,与 Gemini 3.1 Pro 的 1M token 上限持平。在成本上,Gemini 3.1 Pro 的计费远低于 GPT-5.5:Gemini 输入约每百万$2、输出$12,而 GPT-5.5 Pro 则高达输入$30、输出$180。
隐私与安全方面差异显著:OpenAI 默认将用户交互内容用于模型训练,用户需主动选择退出;Google 明确表示不将用户提示或内容用于训练模型。
背景与模型概述
OpenAI 的 ChatGPT 产品在最新阶段使用 GPT-5.5 模型,是继 GPT-5.4 之后的又一迭代升级。GPT-5.5 在前代基础上做了多方面改进,特别强调更高的推理效率和编码能力。根据官方介绍,GPT-5.5 在各种内部评测中普遍优于 GPT-5.4:在 OpenAI 的 Terminal-Bench 2.0 编程基准中取得了 82.7% 的准确率,比 GPT-5.4 有显著提高。
GPT-5.5 在处理系统性问题和维护上下文方面也表现更好。部署层面,OpenAI 提供常规版和 GPT-5.5 Pro 等不同配置,专业版支持高达 1M tokens 的上下文,并可以通过"Fast Mode"加速推理。
Google 的 Gemini 系列是 DeepMind 与 Google 研究院联合开发的多模态大模型。Gemini 3.1 Pro 是 2026 年 2 月发布的最新版本,定位为处理"更复杂任务"的旗舰模型。Gemini 3.1 Pro 依然基于混合专家(MoE)架构,可处理文本、图像、音频、视频和代码等多种数据源。
在升级说明中,Google 强调 3.1 Pro 在高级推理任务上的性能提升:在 ARC-AGI-2 逻辑推理基准中拿到 77.1%(是上一代 3 Pro 的 2 倍水平)。训练与硬件细节公开较少,但模型卡指出支持至多 1M tokens 的输入上下文,输出上限 64K tokens。
性能对比
从可获得的基准来看,Gemini 3.1 Pro 在综合知识和逻辑推理任务上略领先 GPT-5.5。在多语言知识问答(MMLU)上得分 92.6%,超过已知的 GPT-4 的 86.4%,且GPT-5.5 预计在此基础上有所提升但官方未公布具体数值。
编码和复杂任务方面,GPT-5.5 表现突出:在 Terminal-Bench 2.0 编程测试中,GPT-5.5 的准确率为 82.7%,明显高于前代。在上下文理解方面,两者均支持极长的对话历史:GPT-5.5 Pro 版最大上下文长度高达 100万 token,与 Gemini 3.1 Pro 的 1M token 上限相当。
生成质量方面,无公开对比数据,业内普遍认为两者都能提供高质量文本输出。测试人员反馈 GPT-5.5 在商业、法律、教育等专业领域回答更周全,而 Gemini 在多模态和多语言检索上更有优势。
性能雷达示意
| 维度 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|
| 知识问答 (MMLU) | 86.4% (GPT-4) | 92.6% |
| 编程 (Terminal-Bench) | 82.7% | 未公开 |
| 常识推理 | ~95% | ~95% |
| 多模态理解 | 有限 | 80.5% (MMMU) |
| 逻辑推理 (ARC-AGI-2) | 未公开 | 77.1% |
| 上下文长度 | 1M tokens | 1M tokens |
速度与延迟
OpenAI 宣称 GPT-5.5 在速度上与 GPT-5.4 相当,并提供了 Fast Mode 选项以进一步加速(Fast Mode 生成速率提高 1.5 倍)。实际测算中,GPT-5.4 Turbo 的生成速度约为 18ms/词。
Google 在 Gemini 3 系列中也不断优化延迟。虽然官方未公布具体的时延数据,但通过硬件和算法改进,3.1 Pro 提升了每 token 计算效率。Gemini 1.5 系列相比以前版本提高了输出速度的两倍,延迟降低到三分之一。
两者在实际应用中都达到了行业领先的实时响应水平。
成本与定价
GPT-5.5
| 版本 | 输入 (每1M token) | 输出 (每1M token) |
|---|---|---|
| GPT-5.5 Pro | $30 | $180 |
| ChatGPT Plus | $20/月(含一定额度) | — |
Gemini 3.1 Pro
| 上下文大小 | 输入 (每1M token) | 输出 (每1M token) |
|---|---|---|
| ≤200K tokens | $2.00 | $12.00 |
| >200K tokens | $4.00 | $18.00 |
Gemini 3.1 Pro 的成本约为 GPT-5.5 的 1/15,对长会话和高并发场景更友好。Gemini 还支持批量调用折扣以及上下文缓存机制。
隐私与安全
| 维度 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|
| 数据训练 | 默认使用对话内容训练(可退出) | 不使用用户输入训练 |
| 企业版保护 | 付费版默认不训练 | 企业环境严格隔离 |
| 安全机制 | 内容过滤器 + 人工审查 | 多轮安全测试 + 红队评估 |
在隐私政策方面,OpenAI 与 Google 存在显著差异。OpenAI 非企业版 ChatGPT 默认会将用户提供的对话内容用于模型训练(用户可在隐私设置中选择退出)。Google 明确标注:Gemini 不会将你的提示或回复作为训练模型的数据。
优缺点总结
GPT-5.5
- ✅ 多年迭代的对话能力,生态成熟
- ✅ 编程和工程任务优势明显
- ✅ 低延迟,插件生态丰富
- ❌ API 成本极高
- ❌ 默认数据使用政策可能引发隐私顾虑
Gemini 3.1 Pro
- ✅ 超强多模态与推理能力
- ✅ 1M 上下文窗口,成本低
- ✅ 不训练用户数据,企业友好
- ❌ 生态相对较新
- ❌ 部分任务尚未大规模实测公布
综合对比表
| 指标 | GPT-5.5 (ChatGPT) | Gemini 3.1 Pro (Google) |
|---|---|---|
| 模型参数 | 未公开 | 未公开 |
| 上下文窗口 | 最长 1M tokens | 最长 1M tokens |
| Terminal-Bench | 82.7% | 未公开 |
| MMLU | 86.4% (GPT-4) | 92.6% |
| 延迟 | 与 GPT-5.4 相当 | 未公开 (已有优化) |
| 成本 (1M token 输入) | $30 | $2 (≤200K) / $4 (>200K) |
| 成本 (1M token 输出) | $180 | $12 (≤200K) / $18 (>200K) |
| 数据隐私 | 默认用于训练(可退出) | 不用于训练 |
结论与建议
- 需要强大对话体验、成熟生态 → 选 ChatGPT/GPT-5.5
- 需要极致推理、多模态、低成本 → 选 Gemini 3.1 Pro
- 隐私敏感企业 → Gemini 的"不训练用户数据"策略更安全
- 大规模部署 → Gemini 成本仅为 1/15,预算友好
参考资料:本文数据来自 OpenAI GPT-5.5 发布文档、OpenAI 隐私说明、Google Gemini 3.1 Pro 博客与模型卡等公开资料。